We have Markov noodles for dinner
I’ve recently started working on a super secret project that needs a decent random text generator. A common way to accomplish this is by using Markov chains. They have been used to generate comics as well as math research papers that even got accepted by a journal.
Markov chains
Markov chains can be described as state machines. Each state is defined by a word that it generates. Transitions to other states depend only on the current state, there’s no memory, and next state is picked randomly based on probabilities of possible transitions.
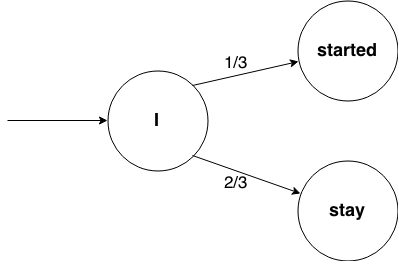
In this example, the initial state is the word “I” and then we have 1/3 probability to generate sentence “I started”, and 2/3 probability to generate sentence “I stayed”.
Let’s try something a bit more complex. You can try generating a sentence by simply following transitions. In this example, all transitions are equally probable.
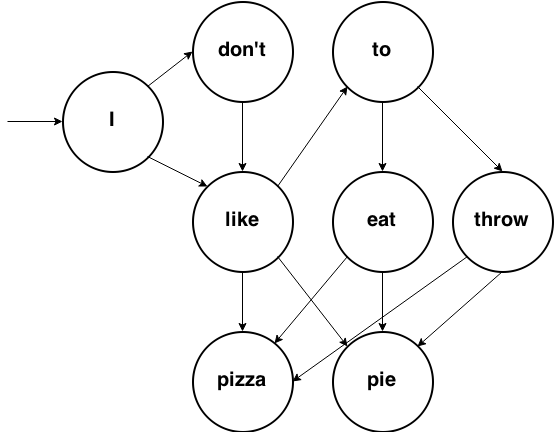
We could generate, for example, “I don’t like pizza.” or “I like to eat pie.”. If we wanted to code this thing, we could use a hash.
dictionary = {
nil => ["I"]
"I" => ["don't", "like"]
"don't" => ["like"]
"like" => ["to", "pizza", "pie"]
"to" => ["eat", "throw"]
"eat" => ["pizza", "pie"]
"throw" => ["pizza", "pie"]
}
## We can transition like this
new_state = dictionary[current_state].sampleBut what about probabilities? Well, because of the way these dictionaries are generated, simplest thing we can do is just add a word multiple times if it’s more likely to appear.
dictionary = {
"Foo" => ["Bar", "Bar", "Bar", "Bleep"]
}In this case, we have 3/4 probability of generating “Bar”, and 1/4 of generating “Bleep”.
Generating dictionaries
We generate these dictionaries by analysing existing text. We go through the text and save preceding word for each word in the text.
## Let analyse "I love pizza. I love cats."
dictionary = {
nil => ["I"]
"I" => ["love"],
"love" => ["pizza.", "cats."]
}You will notice that I added punctuation marks. That’s a simple way to handle them, we just consider them a part of the word. It’s important to note that we need to analyse a lot of text for this to work well.
Things get a little bit more complex when we start introducing dictionary depth. Instead of working with individual words, we can work with sets of two or more words.
Increasing the dictionary depth reduces the randomness of text, but increases its quality - it looks more like a real text. However, if we go too overboard with the depth, our generator will just start outputting same text it read. It seems that dictionary depth of two works best in most cases.
# Let create a depth 2 dictionary
# with: "I love pizza. I love cats."
dictionary = {
[nil, nil] => ["I"],
[nil, "I"] => ["love"],
["I", "love"] => ["pizza.", "cats."]
}Ruby Markov chain gems
So now you know how to use Markov chains to generate text. But is there a gem for that?
Marky Markov is the best I could find, but it has some questionable code in it. When starting a sentence, it will pick a random word and use it if it’s capitalized. If it’s not, it will try again, and it will do this in a loop until it has tried 15 times or found a capitalized word.
Let’s say we are analysing a text that has an average sentence length of 20 words. I haven’t done math in a long time, but I will attempt to calculate the probability of not being able to find capitalized word in 15 tries.
Each time we pick a word we have 19/20 chance of picking out a non-capitalized word. And the chance of picking out a non-capitalized word in 15 tries is (19/20)^15 which is 0,46! That means we will not start sentences correctly almost 50% of the time.
I tried solving this by storing the capitalized words in an separate array, but before my pull request got merged in I decided to try to write my own library, that would do things a bit differently. And hopefully, better and simpler.
Markov noodles
The result is markov_noodles library, that consists of one class that has less than 100 lines of code. It starts sentences correctly all the time, given that input text was correct. And it only uses a hash for a dictionary, no need for a separate storage for capitalized words. Let’s see how it’s done.
# Step 0
input_text = "I love cats. Dogs love pizza."
# Step 1
# Split text by whitespace.
input_array = ["I", "love", "cats.", "Dogs", "love", "pizza."]
# Step 2
# Detect words that end sentences (they have . ! or ? as last character)
# and insert nil after them.
input_array = ["I", "love", "cats.", nil, "Dogs", "love", "pizza.", nil]
# Step 3
# generate dictionary!
dictionary = {
nil => ["I", "Dogs"]
"I" => ["love"],
"love" => ["pizza.", "cats."]
}This way we have a list of all capitalized words, stored in the dictionary under nil key, so we can just use nil as a starting word and it works! Magically!

We’ll that’s it! I hope you learned something. I like Markov chains because they work really well but are easy to understand.
Have fun and don’t forget to check out markov_noodles library.